数据结构与算法(六)——跳表
跳表介绍
跳表(Skip list):是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找,可以支持快速的插入、删除、查找操作。
Redis 中的有序集合(Sorted Set)就是用跳表来实现的。
图解跳表
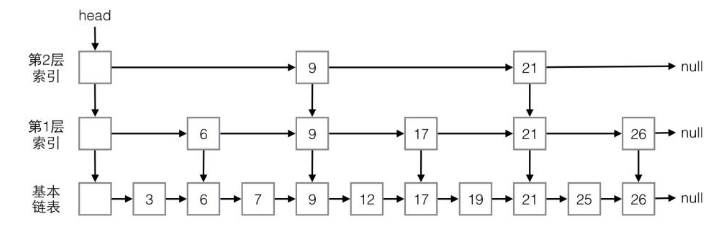
从上图可知,跳表就是链表加多级索引的结构。
作为一种动态数据结构,我们需要某种手段来维护索引与原始链表大小之间的平衡,如果链表中结点多了,索引结点就相应地增加一些,避免复杂度退化,以及查找、插入、删除操作性能下降。跳表是通过随机函数来维护这种“平衡性”的。
快速查找的原理
在最高级索引上查找最后一个小于当前查找元素的位置,然后再跳到次高级索引继续查找,直到跳到最底层为止,这时候以及十分接近要查找的元素的位置了(如果查找元素存在的话)。由于根据索引可以一次跳过多个元素,所以跳查找的查找速度也就变快了。
跳表的复杂度
时间复杂度:O(logn)
空间复杂度:O(n)
跳表的代码实现
跳表中存储的是正整数,并且存储的是不重复的1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117public class SkipList {
private static final int MAX_LEVEL = 16;
private int levelCount = 1;
private Node head = new Node(); // 带头链表
private Random r = new Random();
//查询
public Node find(int value) {
Node p = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
}
if (p.forwards[0] != null && p.forwards[0].data == value) {
return p.forwards[0];
} else {
return null;
}
}
//添加
public void insert(int value) {
int level = randomLevel();
Node newNode = new Node();
newNode.data = value;
newNode.maxLevel = level;
Node update[] = new Node[level];
for (int i = 0; i < level; ++i) {
update[i] = head;
}
// record every level largest value which smaller than insert value in update[]
Node p = head;
for (int i = level - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
update[i] = p;// use update save node in search path
}
// in search path node next node become new node forwords(next)
for (int i = 0; i < level; ++i) {
newNode.forwards[i] = update[i].forwards[i];
update[i].forwards[i] = newNode;
}
// update node hight
if (levelCount < level) levelCount = level;
}
//删除
public void delete(int value) {
Node[] update = new Node[levelCount];
Node p = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
update[i] = p;
}
if (p.forwards[0] != null && p.forwards[0].data == value) {
for (int i = levelCount - 1; i >= 0; --i) {
if (update[i].forwards[i] != null && update[i].forwards[i].data == value) {
update[i].forwards[i] = update[i].forwards[i].forwards[i];
}
}
}
}
// 随机 level 次,如果是奇数层数 +1,防止伪随机
private int randomLevel() {
int level = 1;
for (int i = 1; i < MAX_LEVEL; ++i) {
if (r.nextInt() % 2 == 1) {
level++;
}
}
return level;
}
//打印全部数据
public void printAll() {
Node p = head;
while (p.forwards[0] != null) {
System.out.print(p.forwards[0] + " ");
p = p.forwards[0];
}
System.out.println();
}
//定义节点
public class Node {
private int data = -1;
private Node forwards[] = new Node[MAX_LEVEL];
private int maxLevel = 0;
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("{ data: ");
builder.append(data);
builder.append("; levels: ");
builder.append(maxLevel);
builder.append(" }");
return builder.toString();
}
}
}
redis 有序集合使用跳表的原因
更容易实现
相比红黑树更加易懂、好写,可读性更好。
Ps:很多编程语言 Map 类型都是使用红黑树实现的。
更加灵活
可以通过改变索引构建策略,有效平衡执行效率和内存消耗